Feb
18
2022
使用 Flink Hudi 构建流式数据湖平台

 分类:
分类: 已被围观
已被围观 一、Apache Hudi 101
 修改搜图
修改搜图
 修改搜图
修改搜图
 修改搜图
修改搜图
 修改搜图
修改搜图
 修改搜图
修改搜图
 修改搜图
修改搜图
二、Flink Hudi Integration
 修改搜图
修改搜图
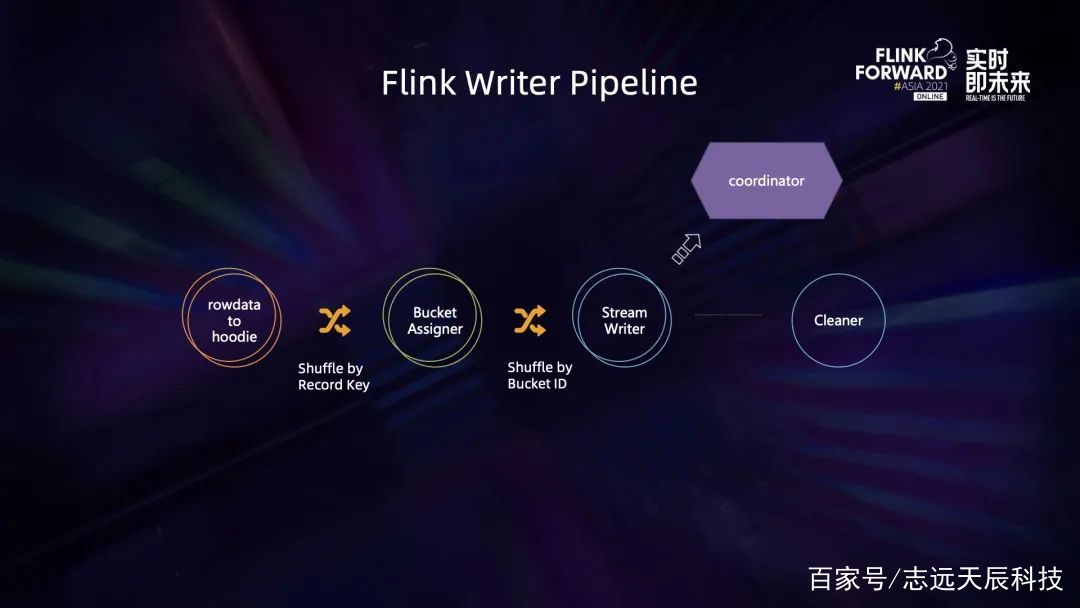
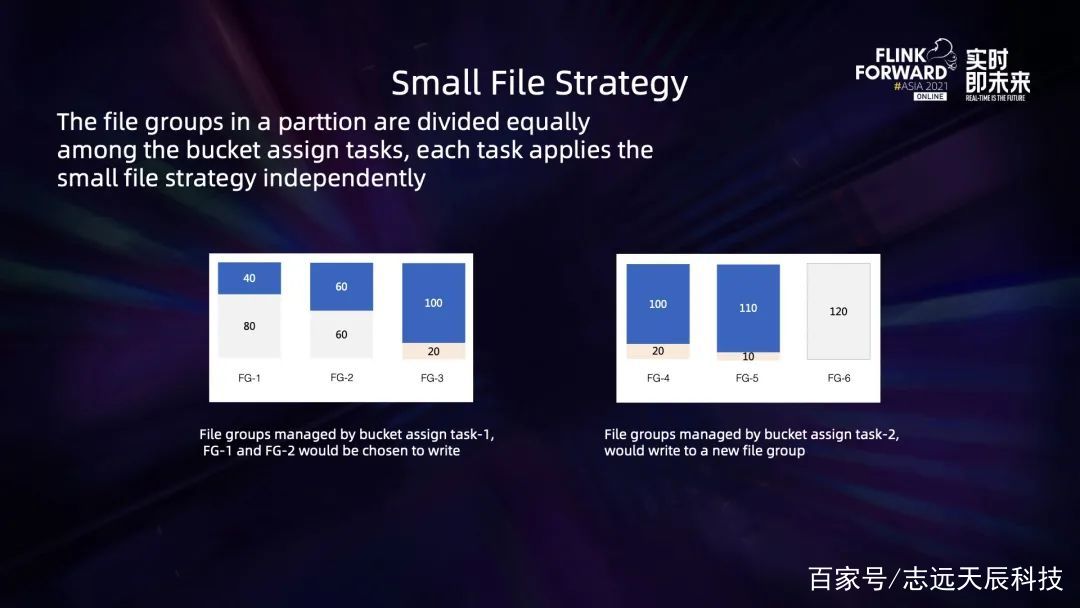 修改搜图其时的设计中,每一个 bucket assign task 都会持有一个 bucket assigner,它独立保护自己的一组 file group。在写入新数据或非更新 insert 数据的时分,bucket assign task 会扫描文件视图,优先将这一批新的数据写入到被判定为小 bucket 的 file group 里。比方上图, file group 默许巨细是 120M,那么左图的 task1 会优先写到 file group1和 file group2,留意这儿不会写到 file group3,这是因为 file group3 现已有 100M 数据,关于比较接近方针阈值的 bucket 不再写入能够避免过度写扩大。而右图中的 task2 会直接写一个新的 file group,不会去追加那些现已写的比较大的 file group 了。
修改搜图其时的设计中,每一个 bucket assign task 都会持有一个 bucket assigner,它独立保护自己的一组 file group。在写入新数据或非更新 insert 数据的时分,bucket assign task 会扫描文件视图,优先将这一批新的数据写入到被判定为小 bucket 的 file group 里。比方上图, file group 默许巨细是 120M,那么左图的 task1 会优先写到 file group1和 file group2,留意这儿不会写到 file group3,这是因为 file group3 现已有 100M 数据,关于比较接近方针阈值的 bucket 不再写入能够避免过度写扩大。而右图中的 task2 会直接写一个新的 file group,不会去追加那些现已写的比较大的 file group 了。
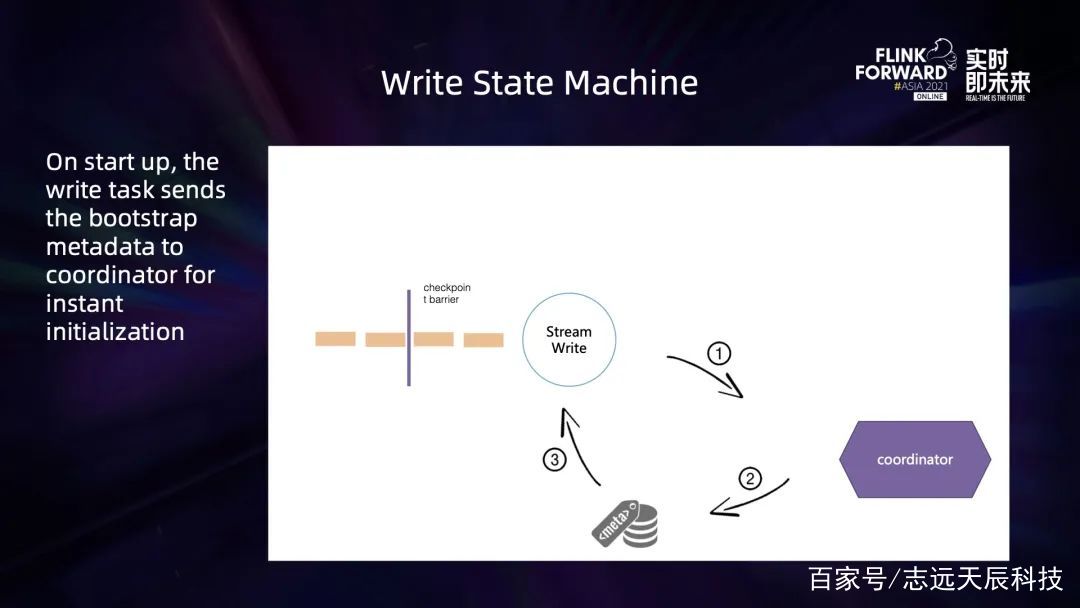 修改搜图
修改搜图
 修改搜图
修改搜图
 修改搜图Flink Hudi read 端也支撑了十分丰富的查询视图,现在首要支撑的有全量读取、历史时刻 range 的增量读取以及流式读取。
修改搜图Flink Hudi read 端也支撑了十分丰富的查询视图,现在首要支撑的有全量读取、历史时刻 range 的增量读取以及流式读取。
 修改搜图
修改搜图
三、Flink Hudi Use Case
 修改搜图
修改搜图
 修改搜图
修改搜图
 修改搜图
修改搜图
 修改搜图未来,社区两个大版别首要的精力仍是放在流读和流写方向,而且会加强流读的语义;别的在 catalog 和 metadata 方面会做自管理;咱们还会在近期推出一个 trino 原生的 connector 支撑,取代其时读 Hive 的方法,进步功率。
修改搜图未来,社区两个大版别首要的精力仍是放在流读和流写方向,而且会加强流读的语义;别的在 catalog 和 metadata 方面会做自管理;咱们还会在近期推出一个 trino 原生的 connector 支撑,取代其时读 Hive 的方法,进步功率。四、Apache Hudi Roadmap

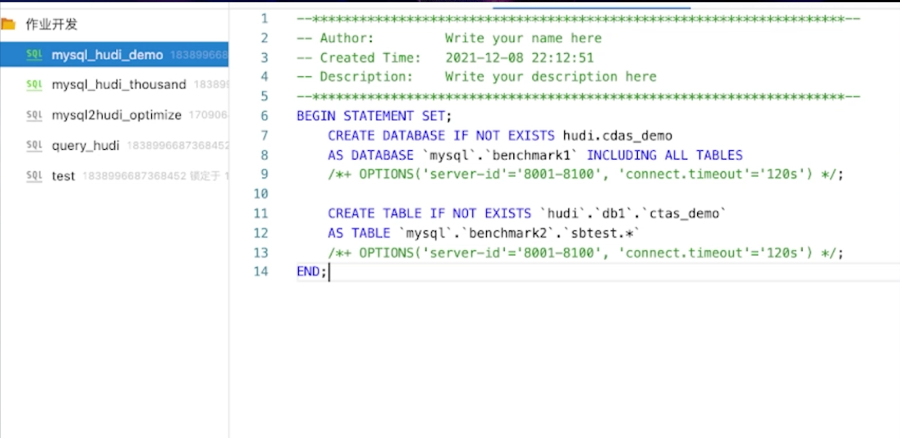 修改搜图
修改搜图
 修改搜图
修改搜图
 修改搜图
修改搜图
本公司销售:阿里云、腾讯云、百度云、天翼云、金山大米云、金山企业云盘!可签订合同,开具发票。
可优惠产品清单

一次合作 终生朋友

部分客户(无排名)










我有话说: